

Tools to navigate bias in NLP algorithms
Machine learning algorithms influence many aspects of our lives in big and small ways; recommendation algorithms suggest articles, videos, and media.
Summary
Machine learning algorithms influence many aspects of our lives in big and small ways; recommendation algorithms suggest articles, videos, and media. Algorithms are used to set your rent, mortgage, and insurance rates. And algorithms are increasingly used in healthcare. When your doctor orders a diagnostic test, there’s a good chance a machine learning algorithm is providing the answer. A care team might consult an algorithm in the electronic health record system to support a decision. Every day, we entrust more of our lives to algorithms.
It’s important to be mindful of bias in these algorithms, or the way in which they behave and can favor certain outcomes. To measure and mitigate bias in algorithms, we need tools to guide us. In this post, we discuss methods that help measure and mitigate bias in NLP algorithms so that we can ultimately build better AI-driven products.
Measuring and mitigating unwanted bias
Algorithmic bias can create worse outcomes for some or better outcomes for others.
For example, A randomized trial conducted by Facebook in 2010 and published in Nature showed that users who saw messages and pictures of friends voting would be more likely to vote. Because the social media feeds are tailored by recommendation algorithms, if certain demographics see these messages versus others, it can affect elections. This effect was dubbed “digital gerrymandering” and is an example of how bias in algorithms can have profound effects.
It’s impossible to create an algorithm that has no bias. Instead, we focus on mitigating unwanted biases or behaviors that can lead to errors in performance or unwanted outcomes.
Metrics
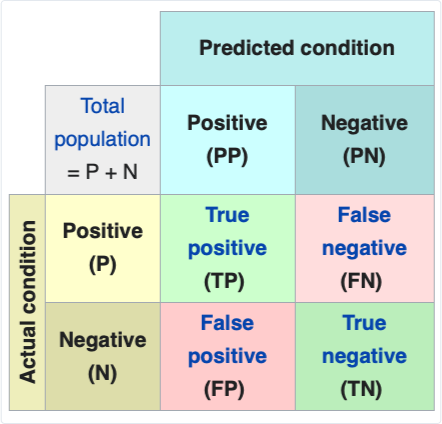
A fundamental tool for understanding the behavior of algorithms is the confusion matrix.
Consider a diagnostic test that predicts whether or not a patient has a risk of heart failure. In the ideal case, everyone with heart failure risk gets notified with 100% accuracy. In practice, there will be errors where some at risk won’t get flagged and some without risk will.
To measure these errors, we use the confusion matrix. In the case of our HF diagnostic:
True Positives: are the number of people at risk accurately flagged.
True Negatives: are the people not at risk who are unflagged.
False Negatives: are those who are at risk but didn’t receive a flag.
False Positives: are those not at risk who were flagged.
The ratio of true positives to all positives defines how precise a diagnostic is (what % of flags are real?). The ratio of true positives to all real positives defines the recall (what % of those at risk are flagged?). A commonly used accuracy metric is the F1 score or the harmonic mean of precision and recall:
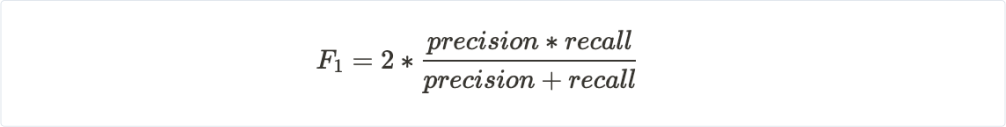
NLP Benchmarks
Benchmarks are a critical way in which we understand the effectiveness of algorithms. They are intended to objectively measure and compare the performance of different algorithms together.
NLP benchmarks have a common set of attributes:
A well-curated set of data that reflect real-world use cases
Appropriate metrics for understanding performance
Tests for statistical significance
The ability to evaluate continuously
Known flaws in benchmarks and how to address them
Recently, existing NLP benchmarks have been critiqued due to the fact that “superhuman” performance is achieved by models but which fail to generalize on external data and domains and have demonstrable bias.
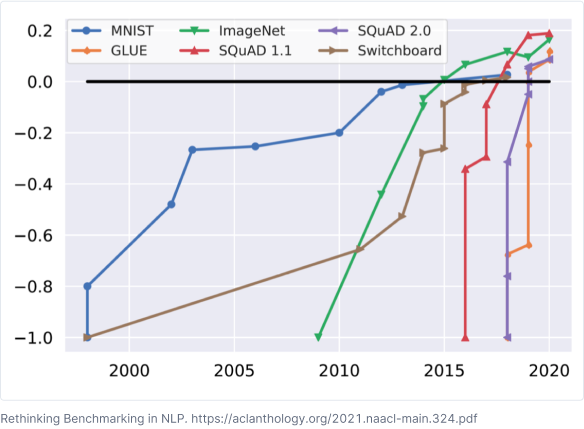
Researchers have proposed possible approaches to addressing these limitations:
Benchmarks should have tests of generalization
Benchmarks should have more ambiguous examples and transparency on inter-annotator agreements and disagreements
Benchmarks should not rely on individual metrics, such as F1, and instead look more critically across multiple metrics to assess where models are useful or have explicit biases
Data and model cards have been proposed to provide documentation and transparency
The CheckList method introduces ways to test for social or racial biases in NLP techniques
Conclusions
Bias is a key concern for algorithms used to develop healthcare products or in directly providing or informing care. To understand how algorithms work, where they are appropriate, and where this is bias to be understood and mitigated, we need navigational tools. NLP benchmarks are terrific tools to help our communities understand existing tools and identify tasks that require more research or development. However, recent issues have NLP benchmarks. Complex algorithms demand complex benchmarks with multiple forms of testing and careful consideration. Finally, we propose better benchmarks for healthcare NLP that can be expanded by the community to accelerate progress in domain-specific language understanding.
Acknowledgments
We would like to thank our team at ScienceIO for their critical input to this post.
Links & Resources
New York Times National Library of Medicine Glue Benchmark Ruder.io Dynabench: Rethinking Benchmarking in NLP
Share:
